puppeteer 是一个 Google 出品的 Node 库,可以用它来操纵 Chrome.
puppeteer 这个单词的发音为 [ˌpʌpɪˈtɪə], 意思是"操纵木偶的人".
安装
安装 puppeteer 时会自动下载 chrome,需要有全局代理.
如果无法下载 puppeteer, 可以在根目录下新建文件 .yarnrc, 填入如下内容:
1
| puppeteer_download_host "https://storage.googleapis.com.cnpmjs.org"
|
例子
新建 index.js, 填入如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
const puppeteer = require('puppeteer');
puppeteer.launch({headless: false}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
await page.screenshot({path: 'baidu.png'});
});
|
最后,进入文件所在路径, 执行 node index.js 命令即可.
browser对象
启动浏览器
可以用puppeteer.launch([options])方法来打开一个chrome浏览器.
该方法返回一个Promise对象, 包含一个Browser对象作为参数.
1
2
3
| puppeteer.launch().then(async browser => { });
await puppeteer.launch();
|
常用参数:
- headless 是否启用"无头模式"(隐藏浏览器界面), 默认为true
- executablePath 指定chrome.exe文件的路径(不使用内置的chromium)
- args 启动chrome的参数
- devtools 是否自动打开DevTools工具,默认为false
参数实例:
1
2
3
4
5
6
7
8
9
10
11
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
executablePath: 'C:/chromium/chrome.exe',
args: [
'--disable-web-security',
'--proxy-server=127.0.0.1:1080',
]
});
})();
|
官方文档 puppeteer.launch
另外, launch方法的defaultViewport参数似乎不起作用,原因未知.使用 --window-size 代替
开启无痕模式
browser.createIncognitoBrowserContext()方法可以进入chrome的进入无痕模式.
该方法返回一个Promise对象, 包含一个Browser对象作为参数.
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const context = await browser.createIncognitoBrowserContext();
const page = await context.newPage();
await page.goto('https://example.com');
await context.close();
await browser.close();
})();
|
新建标签页
使用browser.newPage()方法新建标签页.
该方法返回一个Promise,包含一个Page对象作为参数.
例子:
1
2
3
4
5
6
7
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
})();
|
获取所有标签页
使用browser.pages()方法获取所有可见的标签页.
该方法返回一个Promise对象,包含一个Array作为参数.
例子:
1
2
3
4
5
6
7
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
console.log(await browser.pages());
})();
|
获取浏览器默认的user-agent
使用browser.pages()方法获取所有可见的标签页.
返回: Promise(string)
1
2
3
4
5
6
7
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
console.log(await browser.userAgent());
})();
|
Page对象
Page对象表示一个标签页
访问网站
使用page.goto(url[, options])方法访问指定的url.
返回: Promise(Response)
常用的options:
- timeout 超时时间
- watiUntil 何时完成页面加载
- load 触发load事件(默认)
- domcontentloaded 触发DOMContentLoaded事件
- referer Request headers头的referer参数, 优先级高于page.setExtraHTTPHeaders()
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
args: [
'--auto-open-devtools-for-tabs'
]
});
const page = await browser.newPage();
await page.waitFor(1000);
await page.goto('https://www.example.com', {
waitUntil: 'domcontentloaded',
referer: 'https://www.test.com'
});
})();
|
获取Cookies
使用page.cookies([url])获取页面的cookies.
该方法返回: Promise(Array)
1
2
3
4
5
6
7
8
9
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
console.log(await page.cookies());
})();
|
page.cookies返回的cookies如下.其中的name为cookie名, value为cookie值:
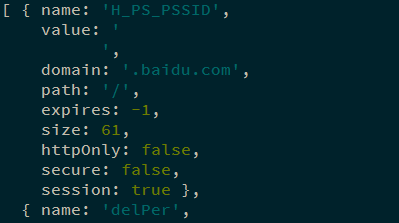
可以用如下方法将其转换为string格式:
1
| const cookiesStr = cookies.map(cookie => `${cookie.name}=${cookie.value}`).join(";");
|
设置Cookies
1 设置单个cookies值
使用page.setCookie(...cookies)设置cookies值.
返回: Promise(undefined)
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.example.com');
await page.setCookie({
name: 'foo',
value: 'bar'
}, {
name: 'foo1',
value: 'bar2'
});
await page.setCookie.apply(page, [{
name: 'foo2',
value: 'bar2'
}]);
console.log(await page.cookies());
})();
|
官方文档 setCookie
注意,chrome浏览器地址栏中的"查看Cookie"很不靠谱.修改/删除cookie后,显示的可能还是原来的cookie.
推荐使用document.cookie方法来查看cookie有没有更新.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
devtools: true
});
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
await page.waitFor(2000);
await page.setCookie({
name: 'BIDUPSID',
value: '123',
domain: '.baidu.com',
path: '/',
httpOnly: false,
secure: false,
session: false
});
page.evaluate(() => console.log(document.cookie));
})();
|
删除cookie
page.deleteCookie(...cookies)
返回: Promise(undefined)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
devtools: true
});
const page = await browser.newPage();
await page.goto('https://www.baidu.com');
await page.deleteCookie({
name: 'BAIDUID',
domain: '.baidu.com',
});
page.evaluate(() => console.log(document.cookie));
})();
|
获取Dom
使用page.$(selector)获取单个的Dom元素, 相当于document.querySelector
返回: Promise(ElementHandle || null)
使用page.$$(selector)获取多个的Dom元素, 相当于document.querySelectorAll
返回: Promise(Array(ElementHandle))
ElementHandle是一个Object对象,而非DOM元素.其储存了对应DOM元素的信息.
获取Dom元素的文本内容
方法1:
1
2
3
4
| const bodyElHandle = await page.$('body');
const text = await page.evaluate(bodyEl => bodyEl.innerText, bodyElHandle);
const text = await page.evaluate(bodyEl => bodyEl.textContent, bodyElHandle);
|
方法2:
1
2
3
4
| const bodyElHandle = await page.$('body');
const prop = await bodyElHandle.getProperty('innerText');
const text = await (prop.jsonValue());
|
方法3:
1
| const text = await page.$eval('body', el => el.innerText);
|
参考
获取多个元素的文本内容:
1
| const text = await page.$$eval('div', (els) => els.map(el => el.innerText));
|
参考
或:
1
2
| const elHandles = await page.$$('div');
const text = await page.evaluate((...els)=> els.map(el => el.innerText) , ...elHandles);
|
注意, 不可以直接把page.$$()方法返回的Array直接作为参数传递给page.evaluate,会报错.
1
2
3
| const elHandles = await page.$$('div');
const text = await page.evaluate((els) => els.map(el => el.innerText), elHandles);
|
这是因为 puppeteer 的很多方法都不支持传入"包含或嵌套JSHandle/ElementHandle的对象"作为参数, 例如page.evaluate page.$eval等
1
2
3
4
|
const elHandles = await page.$$('div');
const text = await page.$eval('body', (body, els) => body.innerText, elHandles);
|
另外,不可以直接返回DOM对象本身
1
2
| const el = await page.$eval('body', el => el);
console.log(el);
|
这是因为DOM对象不能被转化成JSON
1
| JSON.stringify(document.body);
|
参考
获取属性值
同上
暂停
1
2
| // 暂停一秒
page.waitFor(1000)
|
Page事件
类似DOM的addEventListener,page对象也支持响应多种事件.
可以用page.on(事件名, 回调函数)方法来向页面添加事件.
拦截request请求
可用page.on('request', callback)方法来拦截request请求
必须启用"请求拦截器",才能使request.abort, request.continue 和 request.respond 方法生效.
否则会报错: Request Interception is not enabled!
1
2
|
await page.setRequestInterception(true);
|
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
devtools: true
});
const page = await browser.newPage();
const url = 'https://www.baidu.com/';
await page.setRequestInterception(true);
page.on('request', async (request) => {
if (request.url() === url) {
request.continue();
return;
}
request.abort();
});
await page.waitFor(500)
await page.goto(url)
})();
|
注意上面代码request.continue()后的return.
如果对request重复调用不同的handle,则会触发错误: Request is already handled!
例如:
1
2
3
4
5
| if (request.url() === url) {
request.continue();
}
request.abort();
|
启用拦截请求器会禁用页面缓存(版本 1.9 之后).
如希望在开启拦截的同时使用缓存, 则需使用 1.9 之前的版本.或用 Network.setBlockedURLs 代替 setRequestInterception.
https://github.com/puppeteer/puppeteer/issues/2905
1
| await page._client.send('Network.setBlockedURLs', { urls: [...blackList, '.jpg', '.png'] });
|
看起来 Network.setBlockedURLs 有些链接没办法阻止,例如js添加的iframe,具体原因未知
拦截图片加载
在request事件中,可用request.resourceType()方法获取request请求的文件类型,从而判断是否需要拦截该请求.
该方法返回String, 可能返回的值有: document,stylesheet,image,media,font,script,texttrack,xhr,fetch,eventsource,websocket,manifest,other.
例子, 不加载图片:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
devtools: true
});
const page = await browser.newPage();
const url = 'https://www.baidu.com/';
await page.setRequestInterception(true);
page.on('request', async (request) => {
if (request.resourceType() === 'image') {
request.abort();
return;
}
request.continue();
});
await page.waitFor(1000)
await page.goto(url)
})();
|
也可以拦截url请求, 然后返回别的图片:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| const fs = require('fs-extra');
const puppeteer = require('puppeteer');
const __IMAGE__ = fs.readFileSync('./img/success.jpg');
(async () => {
const browser = await puppeteer.launch({
headless: false,
devtools: true
});
const page = await browser.newPage();
const url = 'https://www.baidu.com/';
await page.setRequestInterception(true);
page.on('request', async (request) => {
if (request.resourceType() === 'image') {
request.respond({
state: 200,
contentType: 'image/jpeg',
body: __IMAGE__
})
return;
}
request.continue();
});
await page.waitFor(1000)
await page.goto(url)
})();
|
文档 request.respond
注意: request.respond方法不支持返回dataURL类型的数据.
其他
下载图像
puppeteer没有直接提供一个API来导出图像,需要用别的方法下载图片.
方法1,用axios下载图像:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| const fs = require('fs-extra');
const puppeteer = require('puppeteer');
const axios = require('axios');
const dwImage = async (url, headers) => {
const response = await axios.get(url, {
headers,
responseType: 'arraybuffer'
});
fs.writeFileSync('./logo.png', response.data);
};
(async () => {
const browser = await puppeteer.launch({
headless: true,
devtools: true,
args: [
'--proxy-server="direct://"',
'--proxy-bypass-list=*'
]
});
const url = 'https://www.baidu.com/';
const page = await browser.newPage();
await page.goto(url);
const imageUrl = await page.$eval('#lg img', (imgEl) => imgEl.src);
dwImage(imageUrl, {
referer: url,
'user-agent': await browser.userAgent()
});
browser.close();
})();
|
方法2,使用canvas导出dataURL:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| const fs = require('fs-extra');
const puppeteer = require('puppeteer');
const getDataURLFromImg = async (imgEl) => {
console.log(imgEl);
const canvas = document.createElement('canvas');
canvas.width = imgEl.naturalWidth;
canvas.height = imgEl.naturalHeight;
const ctx = canvas.getContext('2d');
ctx.drawImage(imgEl, 0, 0);
return canvas.toDataURL('image/jpeg', 1);
}
const parseDataURL = (dataURL) => {
const matches = dataURL.match(/^data:(.+);base64,(.+)$/);
if (matches.length !== 3) {
throw new Error('Could not parse data URL.');
}
return {
mime: matches[1],
buffer: Buffer.from(matches[2], 'base64')
};
};
const dwImage = async (elementHandle, page, path) => {
const dataURL = await page.evaluate(getDataURLFromImg, elementHandle)
const {
buffer
} = parseDataURL(dataURL);
fs.writeFileSync(path, buffer, 'base64');
};
(async () => {
const browser = await puppeteer.launch({
headless: true,
devtools: true,
args: [
'--proxy-server="direct://"',
'--proxy-bypass-list=*',
'-–disable-web-security',
]
});
const url = 'https://www.baidu.com/';
const page = await browser.newPage();
await page.goto(url);
const imgElHandle = await page.$('#lg img');
await dwImage(imgElHandle, page, './logo.jpg');
browser.close();
})();
|
参考
方法2的一些注意事项:
1 canvas不支持跨域
虽然可以用drawImage加载跨域的图像, 但用toDataURL导出dataURL时会报错: Tainted canvases may not be exported.
需要在启动browser时允许跨域
1
2
3
4
5
| const browser = await puppeteer.launch({
args: [
'-–disable-web-security',
]
}
|
如果服务器端允许,也可以通过配置img的crossorigin属性来支持跨域.
1
| imgEl.setAttribute('crossorigin', 'Anonymous');
|
MDN CORS settings attributes
2 toDataURL导出图像的默认格式为png
调用toDataURL时,如果不传入第一个参数,则默认导出格式为"image/png",这可能会导致图片变大.
如果不需要导出png,则可以设置为jpg/webp
1
| canvas.toDataURL('image/jpeg', 1);
|
MDN toDataUR
3 获取图像的原始大小
img.width/height获取到的是img标签的大小,可用HTML5新增的naturalWidth和naturalHeight获取img图像的原始大小.
1
2
| canvas.width = imgEl.naturalWidth;
canvas.height = imgEl.naturalHeight;
|
Chrome 启动参数
| 参数 |
用途 |
| --disable-web-security |
禁用同源策略(允许跨域) |
| --proxy-server=127.0.0.1:1080 |
设置代理 |
| --proxy-server='direct://' |
禁用代理 |
| --proxy-bypass-list=* |
不走代理的链接 |
| --no-sandbox |
禁用沙箱 |
| --disable-gpu |
禁用GUP |
| --ignore-certificate-errors |
忽略证书错误 |
| --auto-open-devtools-for-tabs |
自动打开调试工具 |
| --remote-debugging-port=9222 |
开启远程调试 |
| --disable-translate |
禁用翻译提示 |
| --disable-background-timer-throttling |
禁用后台标签性能限制 |
| --disable-site-isolation-trials |
禁用网站隔离 |
| --disable-renderer-backgrounding |
禁止降低后台网页进程的渲染优先级 |
| --headless |
无头模式启动 |
| --user-data-dir=./karma-chrome |
设置用户资料的储存位置 |
| window-size=1920,1080 |
窗口尺寸,相当于设置window.outerWidth/outerHeight 注: chromium的窗口分辨率存在限制,在非无头模式下,不能大于浏览器实际分辨率 |
|
|
更多配置参数详解 List of Chromium Command Line Switches « Peter Beverloo
error
1
| UnhandledPromiseRejectionWarning: TimeoutError: Navigation Timeout Exceeded: 30000ms exceeded
|
headless参数为true时可能会触发该bug
例如:
1
2
3
| puppeteer.launch({headless: true})
// or headless的默认值就是true
puppeteer.launch()
|
解决办法,如果操作系统是windows7, 则使用如下参数创建 browser:
1
2
3
4
5
6
7
8
| const browser = await puppeteer.launch({
headless: true,
args: [
'--proxy-server="direct://"',
'--proxy-bypass-list=*'
]
});
|
Headless mode on Windows 7 causes timeout, never completes · Issue #2391 · GoogleChrome/puppeteer · GitHub
参考
官方文档
中文文档