又称: 零宽断言(Zero-width assertion)
什么是位置?
首先要搞清楚,断言匹配的是位置, 不是某个具体的字符串.
可以把位置理解成"空白字符". 例如字符串 ab 可以分解成如下格式,字母 ab 两边的空白字符就是位置.
1 | '' + a + '' + b + '' |
^ 匹配字符串的开始位置, $ 匹配字符串的结尾位置.
可以试试用 String.replace 来把这两个位置替换成下划线.
1 | 'ab'.replace(/^/, '_') // '_ab' |
Lookahead assertion
结构: (?=pattern)
匹配 pattern 前面的位置
可译为: 向前断言 正向肯定预查
1 | /a(?=b)/.exec('ab') // ['a', index: 0, input: 'ab', groups: undefined] |
使用:
1 | // 匹配所有的美元价格 |
验证字符串格式,要求必须同时包含数字 大写字母 小写字母, 且长度在 8~10 间.
1 | const reg = /^(?=.*[a-z]+)(?=.*[A-Z])(?=.*\d+).{8,10}$/ |
正则 (?=.*[a-z]+)(?=.*[A-Z])(?=.*\d+) 匹配到的是最开始的位置
1 | '123abcAB'.replace( /^(?=.*[a-z]+)(?=.*[A-Z])(?=.*\d+)/, '_') // '_123abcAB' |
Negative lookahead assertion
结构: (?!pattern)
匹配 !pattern 前面的位置
可译为: 向前否定断言 正向否定预查
1 | /a(?!b)/.exec('ac') // ['a', index: 0, input: 'ac', groups: undefined] |
匹配 abc000
1 | /abc(?!abc).*/.exec('abcabc000') |
Lookbehind assertion
结构: (?<=pattern)
匹配 pattern 后面的位置
可译为: 向后断言 反向肯定预查
1 | /(?<=a)b/.exec('ab') // ['b', index: 1, input: 'ab', groups: undefined] |
Negative lookbehind assertion
结构: (?<!pattern)
匹配 !pattern 后面的位置
可译为: 向后否定断言 反向否定预查
1 | /(?<!a)b/.exec('cb') // ['b', index: 1, input: 'cb', groups: undefined] |
注意事项
1 Lookbehind 为 ECMA2018 提案, 截止到 2022/4/23 日, Safrai IE 和 低版本 Chrome (61及以下)不支持 Lookbehind,需注意兼容问题
提案地址 GitHub - tc39/proposal-regexp-lookbehind: RegExp lookbehind assertions
caniuse兼容列表 https://caniuse.com/?search=lookbehind
2 Chrome 和 Firefox 实现的 Lookbehind assertion 支持使用 * ? + 符号(在其他的某些语言中不允许使用这些符号)
1 | 'a123'.match(/(?<=[a-z]+)\d+/g) // ['123'] |
具体说明见: RegExp lookbehind assertions · V8
3 这四个断言的 * + 都是非贪婪的
1 | 'ab1ab2'.match(/(?:.+)\d/g) // ['ab1ab2'] |
4 断言没有位置限制,可以在任意位置使用
1 | 'aaabbbc'.match(/a(?!a).*c/g) // ['abbbc'] |
为什么 /(?=.*\d$).*/ 里有个 $ 依然能匹配到 abc1?
因为(?=.*\d$)表示匹配 .*\d$ 前面的位置,也就是字符串的开头.可以理解为: 后边的字符串必须以数值结尾.
5 Lookahead 和 Lookbehind 的区别
断言匹配的是位置,向前断言就是匹配某个 pattern 前面的位置,向后断言就是匹配某个 pattern 后面的位置.
举例来讲:
1 (?=a) 匹配字符串 a 前的位置
2 (?<=a) 匹配字符串 a 后的位置
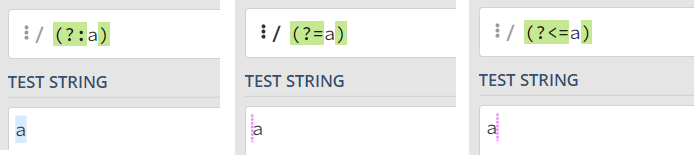
断言和非捕获组(Non-capturing group)的区别
非捕获组的结构: (?:pattern)
非捕获组匹配的是字符串,而断言匹配的是位置
可以用正则测试网站 regex101 来查看二者的区别: https://regex101.com/
总结
1 assertion 匹配位置,而非字符串
2 位置是字符间的空隙,没有宽度
3 lookahead 匹配前面的位置, lookbehide 匹配后面的位置
4 lookahead 的写法是 (?=pattern). lookbehide 的写法是 (?<=pattern),多了一个 <
5 反过来取非就在前面加 negative, negative lookahead
6 negative lookahead 的写法是 (?!pattern), negative lookbehide 的写法是 (?<!pattern).(把=号替换成!)
参考
Assertions - JavaScript | MDN
https://zh.wikipedia.org/wiki/正则表达式
https://2ality.com/2017/05/regexp-lookbehind-assertions.html
Regex Tutorial - Lookahead and Lookbehind Zero-Length Assertions
正则表达式位置匹配攻略 - 知乎
正则表达式30分钟入门教程